ComfyUI学习记录
ComfyUI Learning Log
从 8G 显存出发的 ComfyUI 学习记录
这篇文章记录我用学生党设备学习 ComfyUI 的过程,重点放在 Stable Diffusion 基础工作流、ControlNet 常见控制类型 和 Z-Image 实践。内容不追求百科式覆盖,而是尽量保留真正有用的上手经验。
学习入口
软件来自 B 站的 秋葉aaaki,教程主要参考 ComfyUI Wiki。对刚入门的人来说,先把环境跑通、把默认工作流看懂,比一上来追求复杂节点更重要。
- 软件来源:秋葉aaaki 的个人空间
- 教程参考:ComfyUI Wiki 基础教程
另外补一个很实用的小技巧:新建节点时,直接从节点参数的小圆点拖出一条线,再拉到空白区域,就能快速打开搜索框,这个操作熟练后效率会高很多。
一、Stable Diffusion 基础工作流
我目前最常用的是 SDXL。从今天回看,虽然 Flux 已经很强,但 SD 仍然有一个非常现实的优势:社区资源多、教程多、踩坑经验也多。对个人学习和低成本试错来说,这一点非常重要。
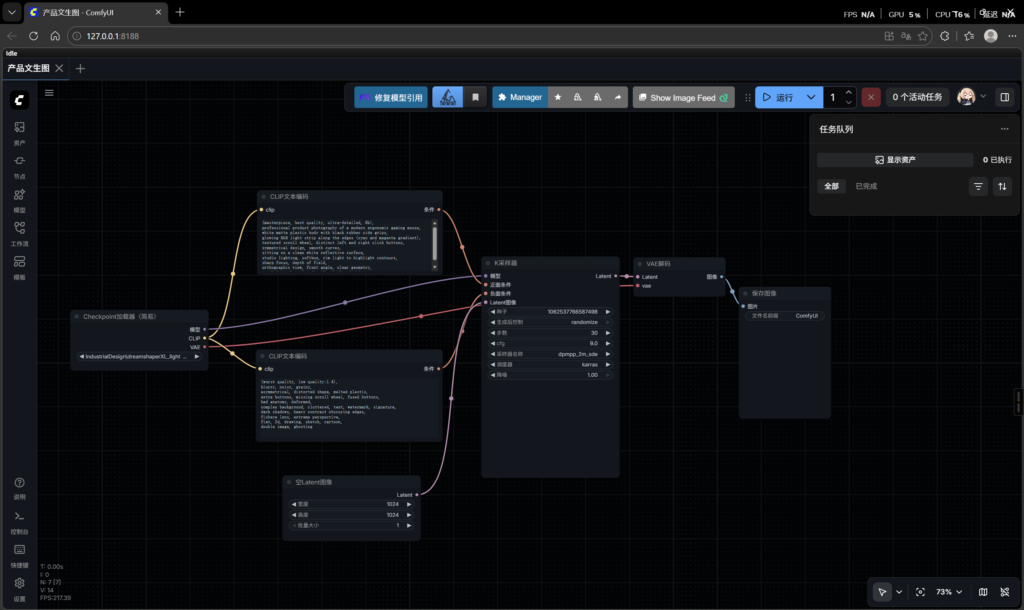
这套默认工作流其实已经足够作为入门骨架。真正影响成图质量的,并不是盲目堆节点,而是先理解几个核心参数分别在控制什么。
提示词
正面提示词尽量具体、负面提示词尽量清晰。像 masterpiece、best quality 这类词常被当作质量保底;负面里加入 worst quality、low quality:1.4 也很常见。
K 采样器
步数决定迭代次数,通常步数更高质量更稳,但时间和显存代价也更高。起步测试我更建议先用 20 步,CFG 常用 9;商品图可以往 11 调,自由度更高的风格图则可以降到 5 到 7。
VAE
不同 VAE 会直接影响最终画面的观感,尤其是颜色与质感。很多时候不一定非要全盘换模型,单独替换 VAE 就能得到明显变化。
CheckPoint
Checkpoint 决定了大模型本身的基础风格。若暂时不考虑 LoRA、ControlNet 这类附加控制,文生图质量调优很大程度就落在模型、提示词和采样器三者上。
如果只是想快速开始,不需要一次把所有概念都啃完。先把默认工作流跑顺,再逐个理解参数变化,比从复杂整合包里“会点不会改”要扎实得多。
二、Stable Diffusion 进阶:ControlNet 的常见控制类型
当基础文生图跑顺之后,真正让画面“可控”起来的就是 ControlNet。随着社区发展,它已经有很多分支,但常见类型大致可以按下面几类来理解。
线条控制类
Canny 适合提边缘结构,MLSD 更适合建筑和室内直线,Lineart 更偏向高质量线稿提取,SoftEdge 则适合不那么严格的结构参考,Scribble/Sketch 适合从草图出发。
深度与结构类
Depth 用亮暗区分前后景,NormalMap 偏向表面凹凸与质感表达,OpenPose 则常用来锁定人体姿态,是角色图里非常实用的一类控制。
语义与分割类
Segmentation 按类别语义生成对应区域,适合做结构明确的分区控制;Inpaint 或局部重绘则更适合小范围修图,保持整张图风格一致。
风格与功能扩展类
Shuffle 强调打散和重组,Recolor 适合重上色,IP-Adapter 可做风格或人脸一致性控制,InstantID、Tile/Blur 则更偏向换脸和高清修复等实战需求。
我自己的感受是,ControlNet 很强,但也更吃硬件。对 8G 显存来说,最关键的不是“什么都装”,而是先挑与你当前目标最相关的控制类型来学。
三、Z-Image 实践记录
在尝试 Z-Image 的过程中,我最直观的感受就是:显存永远是第一道门槛。一开始我换了更低配的 checkpoint 还是爆显存,本来都准备放弃了,后来接触到带 .gguf 后缀的文件,才意识到模型还有进一步压缩的空间。
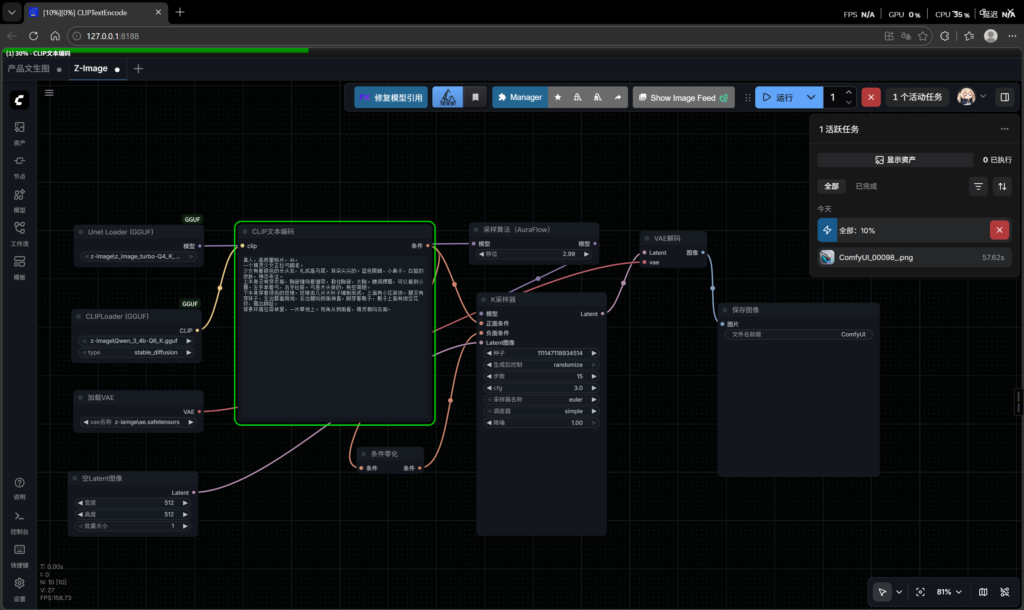
老实说,我现在也还在继续学它背后的原理,但对个人学习来说,很多时候先把流程跑起来,再倒回来理解为什么能跑通,会更符合实际。至少对目前这台机器而言,这已经是一条能落地的方法。