基于LLM的UI自动化:探索大语言模型与移动端UI自动化的深度融合

中期汇报:基于LLM的UI自动化
探索大语言模型与移动端UI自动化的深度融合
1. 项目背景
随着移动应用生态的迅猛发展,用户对智能交互的需求日益增长。传统UI自动化工具(如Appium)依赖预定义脚本,难以应对动态界面和复杂任务。
核心目标
构建一个能够“看懂”手机界面、“听懂”用户指令并自主完成操作的智能代理系统。

图 1:项目背景与概念演示
2. 技术路线
本项目采用了分层架构设计,确保系统各模块解耦且高效协作。
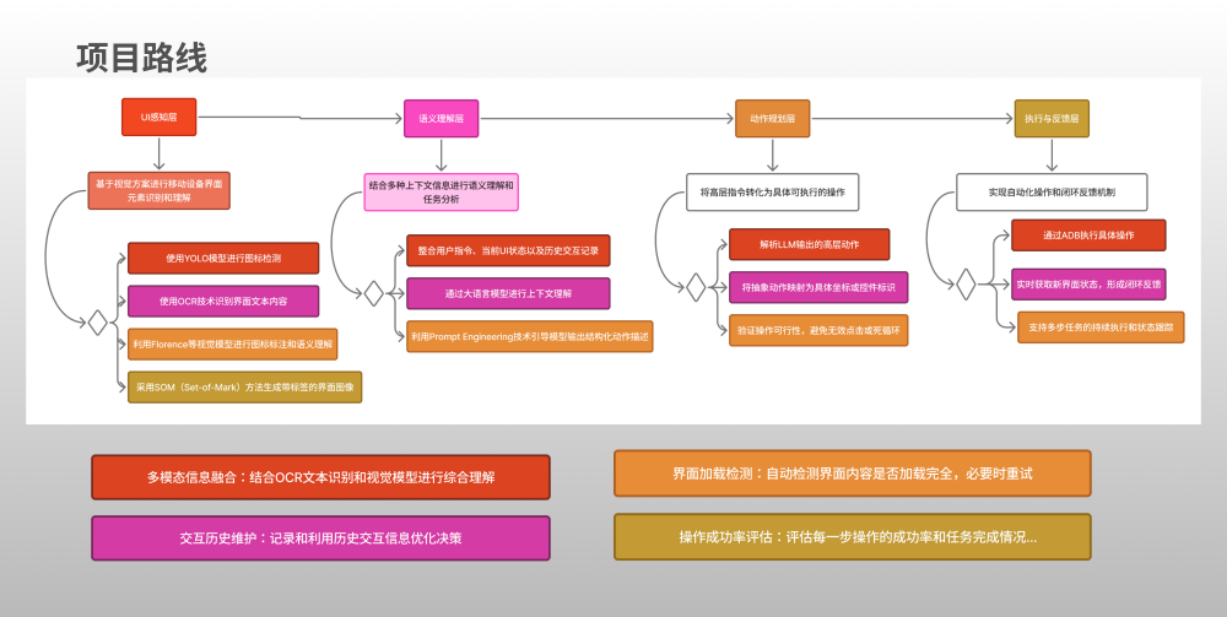
图 2:技术路线架构全景图
UI感知层
- 使用YOLO模型进行图标检测
- 使用OCR技术识别界面文本内容
- 利用视觉模型进行语义理解
语义理解层
- 整合用户指令、当前UI状态及历史记录
- 通过大语言模型进行上下文理解
动作规划层
- 解析LLM输出的高层动作
- 将抽象动作映射为具体坐标或控件标识
执行与反馈层
- 通过ADB执行具体操作
- 实时获取新界面状态,形成闭环反馈
3. 项目目标与设计机会

图 3:项目核心目标与设计机会分析
4. 当前进展
4.1 多App UI识别能力拓展
针对拼多多、得物、淘宝等应用的典型页面构建了结构化UI数据集。
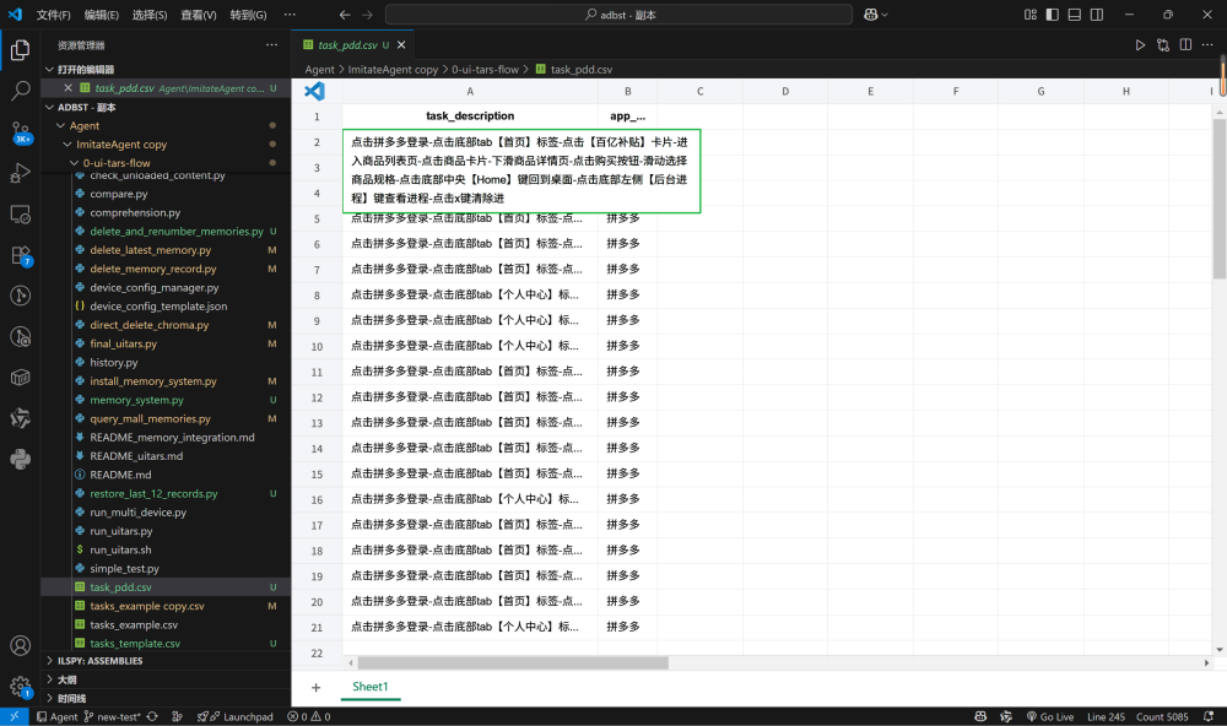
图 4:结构化任务数据集
4.2 知识库驱动的操作增强
构建了轻量级操作知识库,涵盖常见用户意图及异常处理策略。
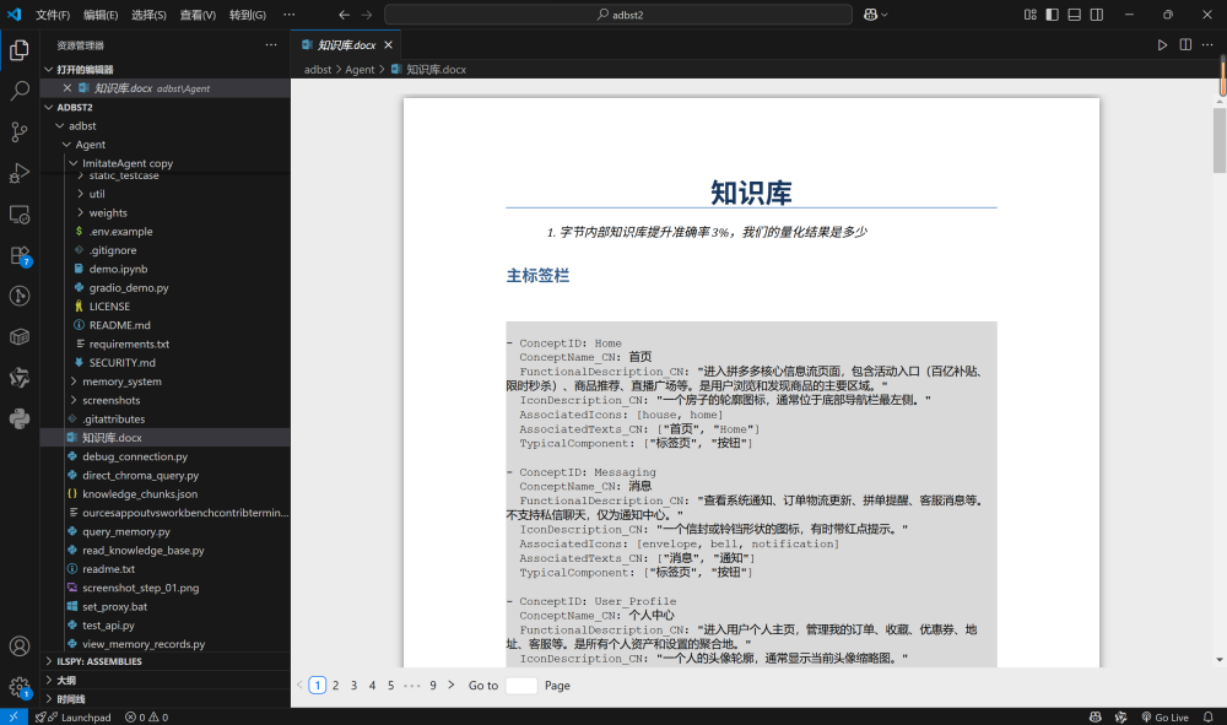
图 5:集成至Agent决策流程
5. 项目意义与创新点
01
从单点到泛化
系统性解决跨App UI理解难题。
02
知识+LLM双驱动
兼顾准确性与灵活性。
03
强调可评测性
引入外部Agent与标准测试集。
6. 下一步计划
- 完善知识库体系:扩展至淘宝、得物。
- 提升UI解析鲁棒性:优化针对动态内容的感知。
- 加速评测体系建设:完成LlamaTouch测试。